Por: @eduardoh Publicado em: 2022-06-27
Graylog para consumo de logs do Webfilter
Objetivo
Testar o comportamento do serviço Graylog para o consumo de logs do Webfilter.
Instalação
Cenário de instalação 1
O cenário 1 consiste em instalar o Graylog e seus recursos no estilo “bare-metal”, ou seja, diretamente no Linux como serviço.
Preparar o envio do arquivo de log relacionado ao webfilter para o serviço do Graylog:
Crie um arquivo em /etc/rsyslog.d com um nome para identificação, por exemplo 10-itflex-webfilter.conf
$ModLoad imfile
$InputFileName /var/log/itflex/webfilter/webfilter.log
$InputFileTag itflex-webfilter
$InputFileSeverity info
$InputFileFacility local5
$InputRunFileMonitor
local5.* @<IP_Graylog>:1514;RSYSLOG_SyslogProtocol23Format
ModLoad: carrega o módulo de importação de arquivos.InputFileName: indica qual arquivo de log será indexado ao Rsyslog.InputFileTag: será o a tag atribuída quando o Rsyslog ler mensagens deste arquivo.InputFileSeverity: é a severidade aplicada ao log.InputFileFacility: é o recurso de facilidade aplicada ao log, utilizada posteriormente como possíveis filtros.InputRunFileMonitor: ativa a monitoração do log indicado.local5.* @<IP_Graylog>:1514;RSYSLOG_SyslogProtocol23Format: padrão para envio do log ao Graylog.
Instalando os requisitos:
Java OpenJDK e Pwgen:
yum install java-latest-openjdk-headless pwgen
MongoDB:
vim /etc/yum.repos.d/mongodb-org.repo
[mongodb-org-4.2]
name=MongoDB Repository
baseurl=https://repo.mongodb.org/yum/redhat/$releasever/mongodb-org/4.2/x86_64/
gpgcheck=1
enabled=1
gpgkey=https://www.mongodb.org/static/pgp/server-4.2.asc
yum install mongodb-org
systemctl daemon-reload
systemctl enable mongod.service
systemctl start mongod.service
systemctl --type=service --state=active | grep mongod
Elasticsearch:
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
vim /etc/yum.repos.d/elasticsearch.repo
[elasticsearch-7.x]
name=Elasticsearch repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/oss-7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
yum install elasticsearch-oss
vim /etc/elasticsearch/elasticsearch.yml
cluster.name: graylog
systemctl daemon-reload
systemctl enable elasticsearch.service
systemctl restart elasticsearch.service
systemctl --type=service --state=active | grep elasticsearch
Sabemos que o Java consome muitas vezes muito recurso do seu hospedeiro, sendo assim, podemos optar em fazer um tunning básico, limitando o uso desses recursos:
vim /etc/elasticsearch/jvm.options
-Xms512m
-Xmx512m
Instalando o Graylog:
rpm -Uvh https://packages.graylog2.org/repo/packages/graylog-4.2-repository_latest.rpm
yum install graylog-server graylog-enterprise-plugins graylog-integrations-plugins graylog-enterprise-integrations-plugins
Gerando senha de acesso a console:
echo -n "Enter Password: " && head -1 </dev/stdin | tr -d '\n' | sha256sum | cut -d" " -f1
Enter Password: semprelinux
a4cdd2f9458548f5e384f8a3f6387fa84a4c476e0954f8335d2bf766ffa6d6f5
vim /etc/graylog/server/server.conf
password_secret = a4cdd2f9458548f5e384f8a3f6387fa84a4c476e0954f8335d2bf766ffa6d6f5
root_password_sha2 = a4cdd2f9458548f5e384f8a3f6387fa84a4c476e0954f8335d2bf766ffa6d6f5
root_timezone = America/Sao_Paulo
http_bind_address = <IP_Graylog>:9000
http_publish_uri = http://<IP_Graylog>:9000/
http_external_uri = http://<IP_Graylog>:9000/
A partir de agora já podemos iniciar o serviço, porém lembre-se, caso o Graylog seja instalado em um servidor que não tenha algum serviço web (apache2, nginx), é necessário preparar para poder acessar a página web.
systemctl daemon-reload
systemctl enable graylog-server.service
systemctl start graylog-server.service
systemctl --type=service --state=active | grep graylog
Lembre-se de criar uma regra no FWFLEX permitindo acesso a porta 9000 de acesso web ao Graylog.
Cenário de instalação 2
O cenário 2 irá apresntar os testes executados com o Graylog utilizando Docker como engine de execução do serviço.
Para o envio dos logs a partir do servidor cliente, execute o passo de criar o arquivo 10-itflex-webfilter.conf contido no passo 1.
Instalando o Docker no AlmaLinux:
dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
dnf install docker-ce docker-ce-cli containerd.io
Instalando o Docker Compose:
sudo curl -L https://github.com/docker/compose/releases/download/X.XX.X/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose
Onde X.XX.X é a versão disponível em:
https://github.com/docker/compose/releases
Aplique as permissões:
sudo chmod +x /usr/local/bin/docker-compose
Testando
docker-compose --version
Docker Compose version v2.6.1
Criando a stack responsável pelo funcionamento do Graylog:
vim /root/graylog/docker-compose.yml
version: '3'
services:
mongo:
image: mongo:4.2
restart: always
networks:
- graylog
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch-oss:7.10.2
restart: always
environment:
- http.host=0.0.0.0
- transport.host=localhost
- network.host=0.0.0.0
- "ES_JAVA_OPTS=-Dlog4j2.formatMsgNoLookups=true -Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
deploy:
resources:
limits:
memory: 1g
networks:
- graylog
graylog:
image: graylog/graylog:4.2
restart: always
environment:
- GRAYLOG_PASSWORD_SECRET=semprelinux
# Password: admin
- GRAYLOG_ROOT_PASSWORD_SHA2=8c6976e5b5410415bde908bd4dee15dfb167a9c873fc4bb8a81f6f2ab448a918
# Alterar para o IP do servidor
- GRAYLOG_HTTP_EXTERNAL_URI=http://172.28.60.36:9000/
entrypoint: /usr/bin/tini -- wait-for-it elasticsearch:9200 -- /docker-entrypoint.sh
networks:
- graylog
restart: always
depends_on:
- mongo
- elasticsearch
ports:
# Graylog web interface and REST API
- 9000:9000
# Syslog TCP
- 1514:1514
# Syslog UDP
- 1514:1514/udp
# GELF TCP
- 12201:12201
# GELF UDP
- 12201:12201/udp
networks:
graylog:
driver: bridge
Iniciando a stack:
* Executar no mesmo diretório onde o arquivo docker-compose.yml está:
docker-compose up -d
Lembrando que esse template utilizado do Graylog foi obtido a partir da documentação oficial. Caso utilizar dessa maneira, será necessário avaliar a utilização de volumes persistentes e também mapear apenas portas necessárias, como Syslog/UDP.
A partir de agora, já podemos seguir com os passos de configuração da ferramenta.
Configurando o Graylog
Criando um input de logs
Precisamos indicar uma fonte de entrada de dados para o Graylog começar a tratar. Para isso iremos indicar o Rsyslog configurado anteriormente (lembre-se que endereçamentos variam de acordo com o cenário)
Caminho: Interface web -> System -> Inputs -> Syslog UDP -> Lauch
Criando um novo input:
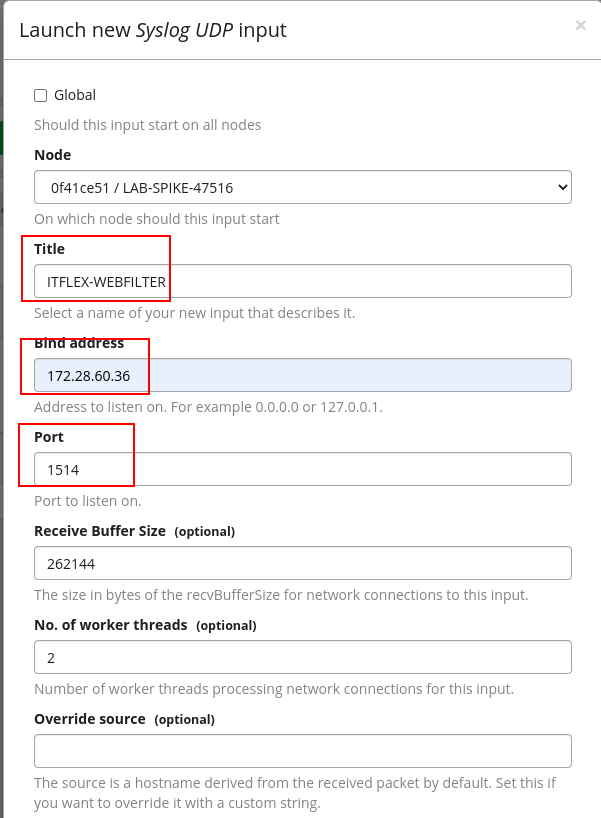
Definindo informações do input:
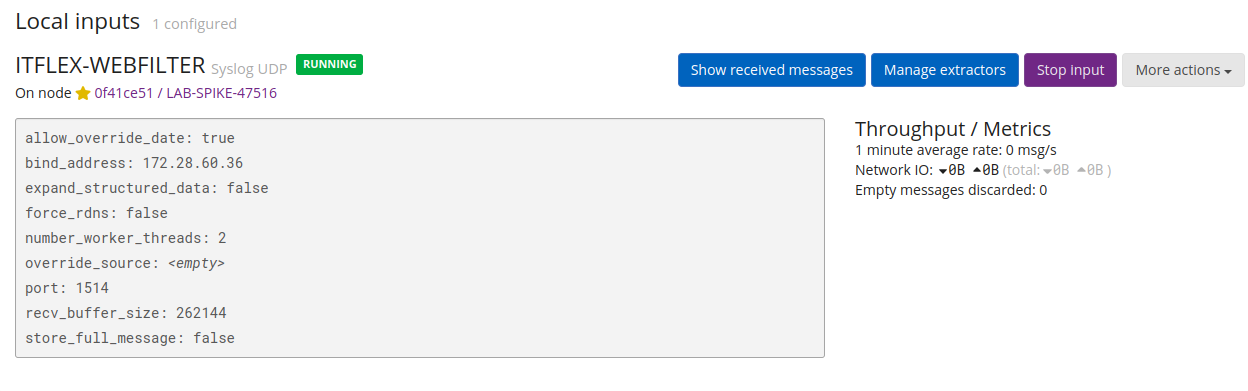
Input criado com sucesso:
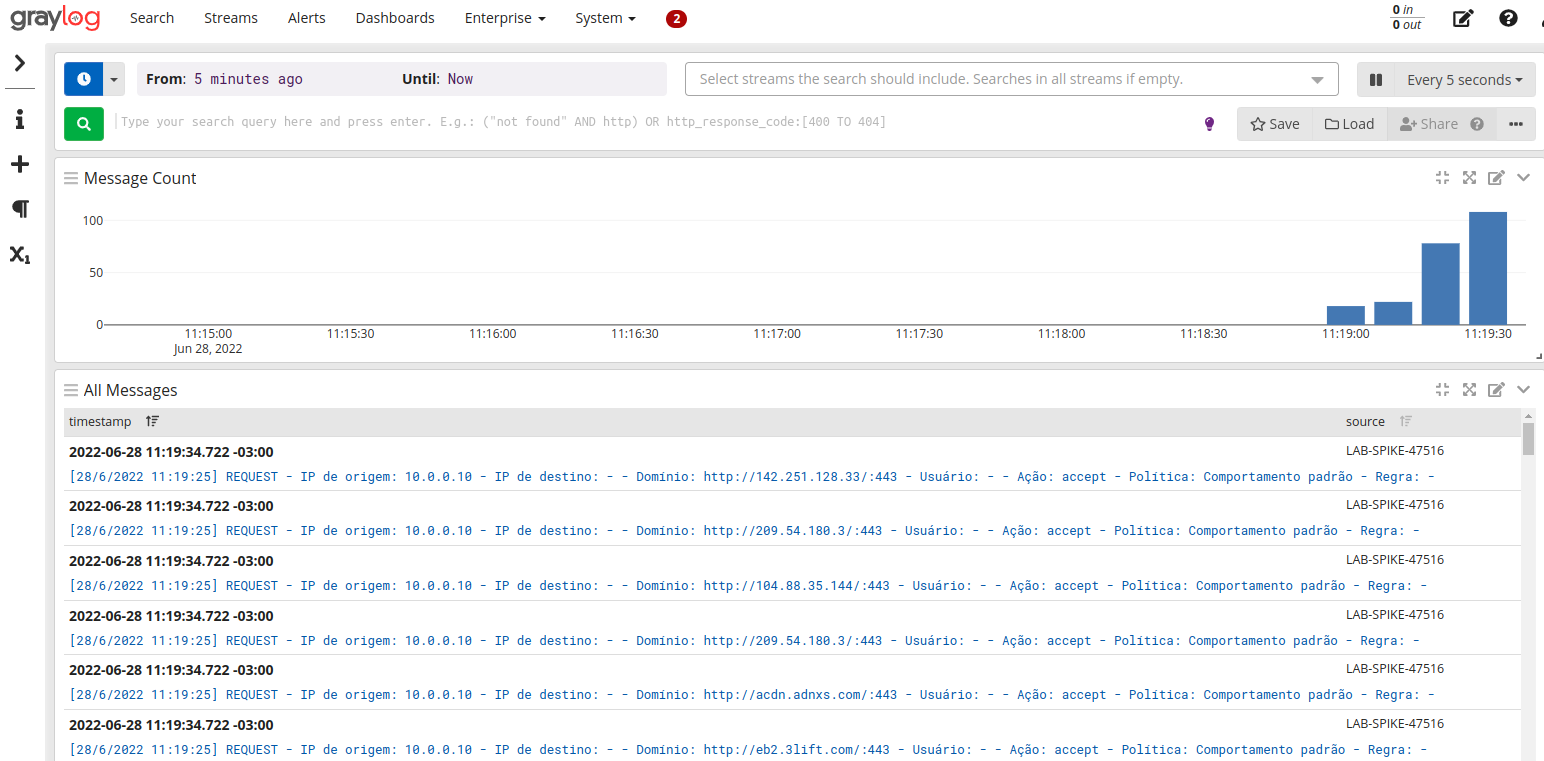
Visualizando os dados recebidos:
Criando extratores de logs
Os extratores permitem que sejam possível efetuar extração de mensagens que estejam embutidas nos logs recebidos, filtrando e melhorando a visualização e permitindo criação de dashboards, eventos, entre outros.
Caminho: Interface web -> System -> Inputs -> Manage extractors
Iniciando a criação de um novo extrator:
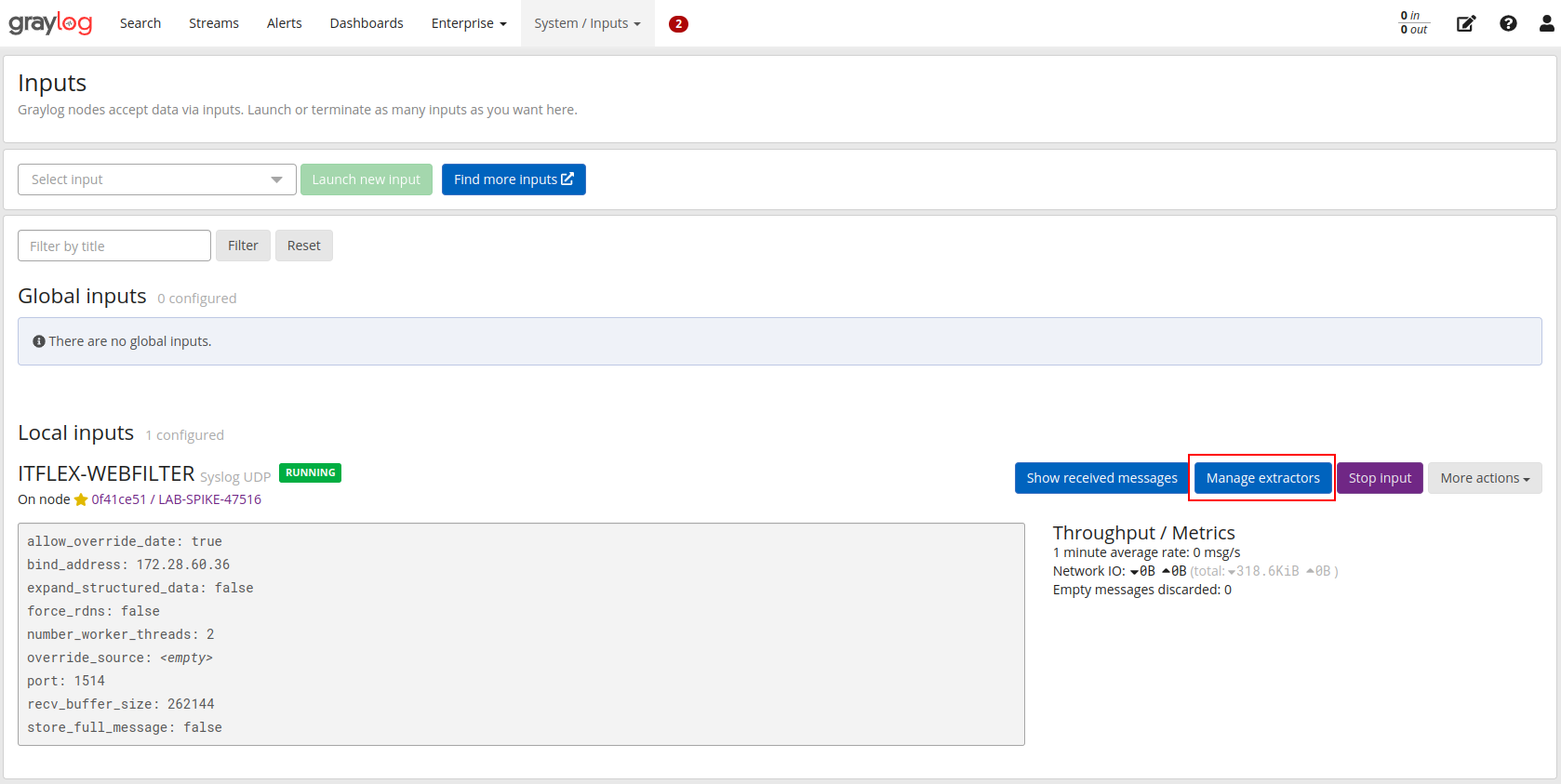
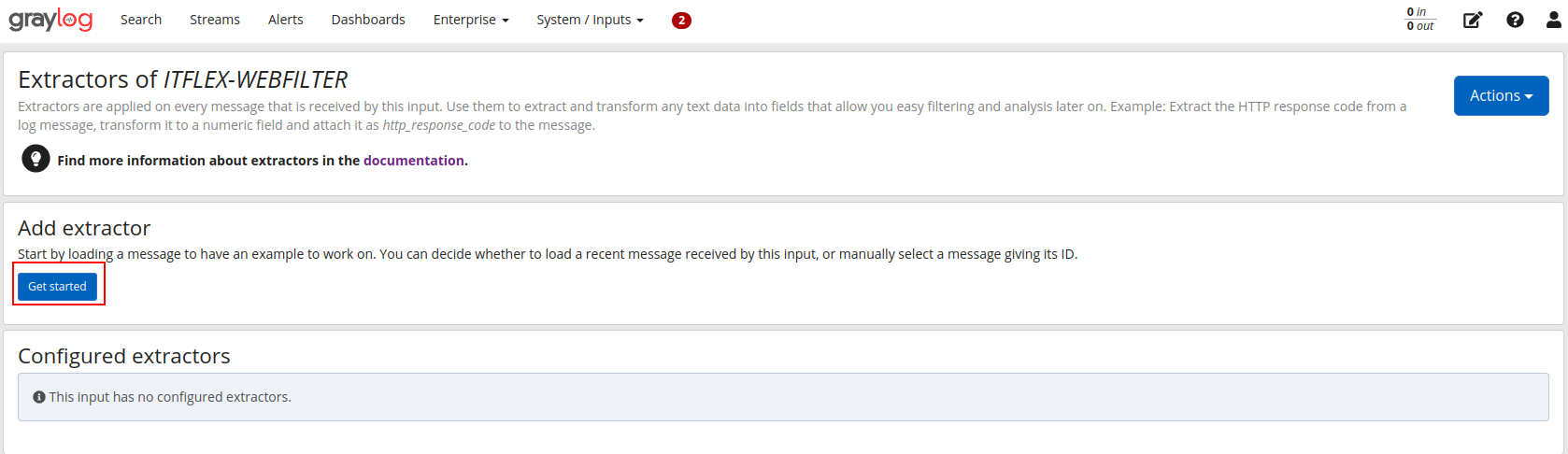
Capturando uma mensagem de exemplo para começarmos a interagir com o padrão:
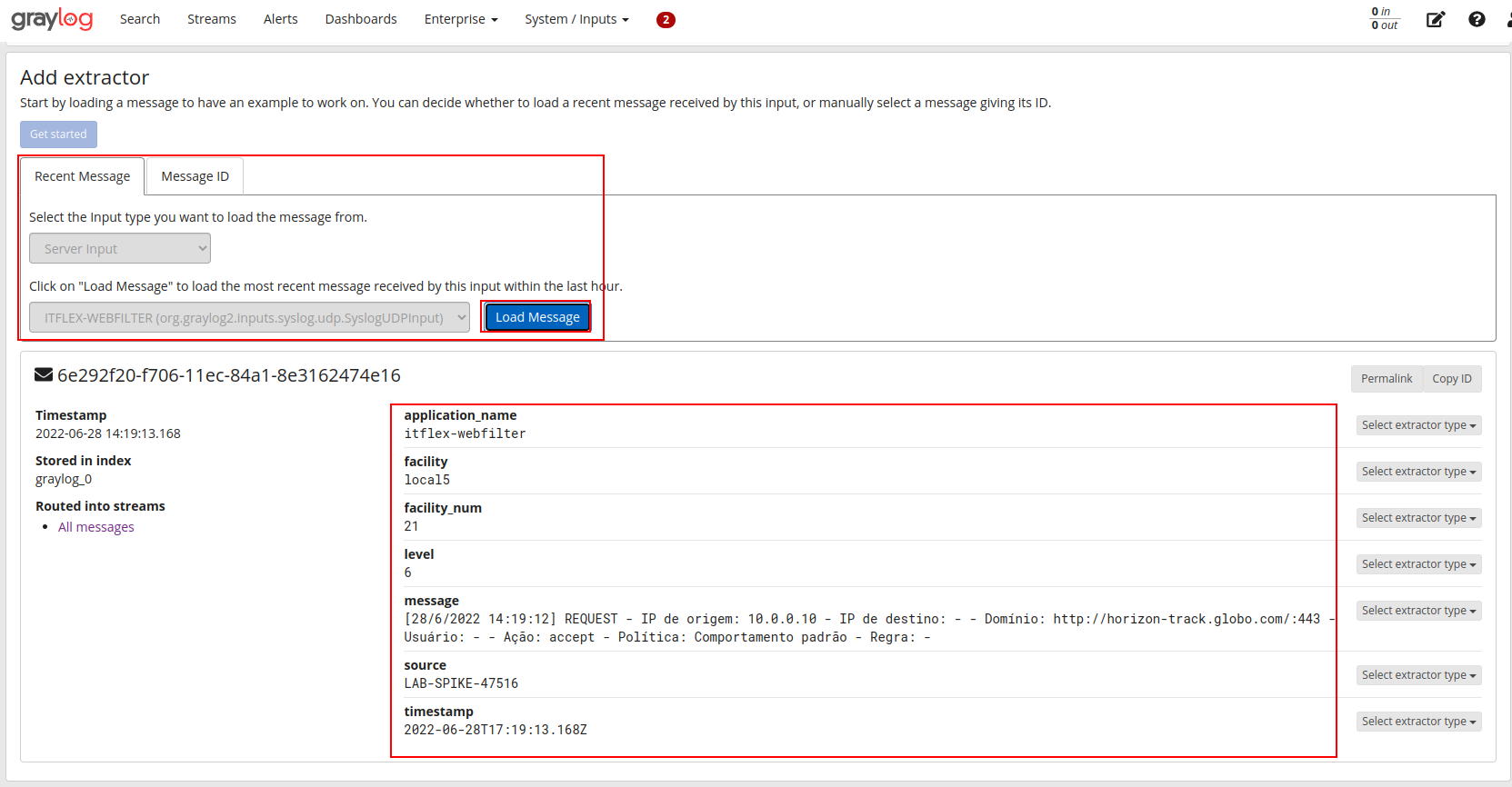
Criando um extrator a partir da message do log utilizando expressão regular:
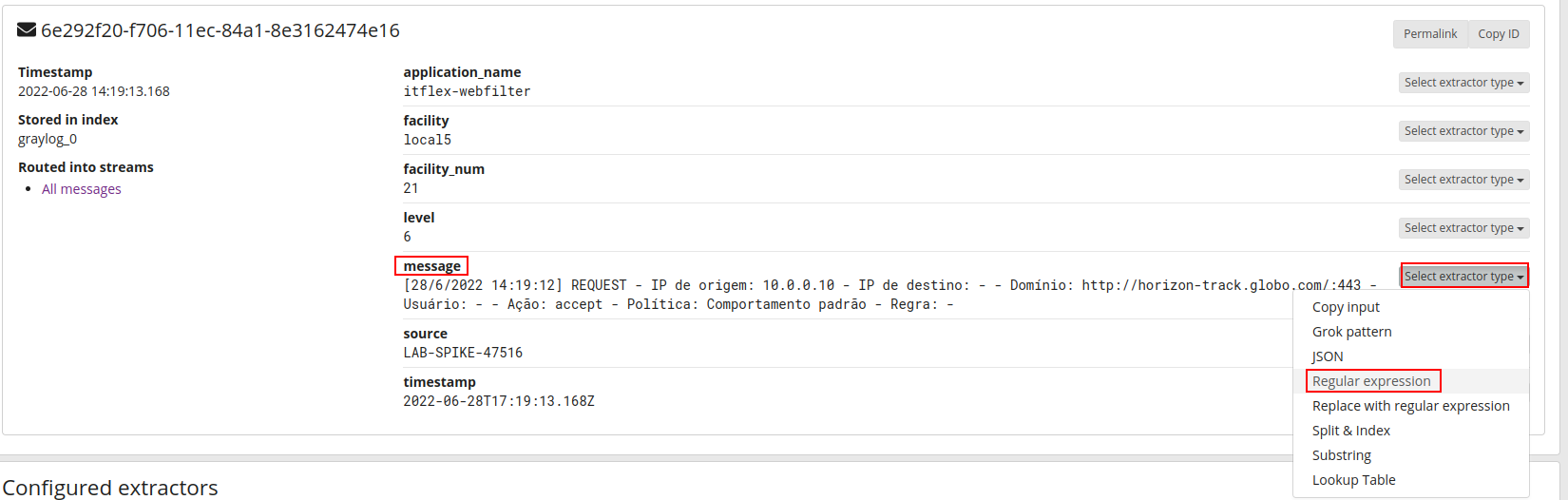
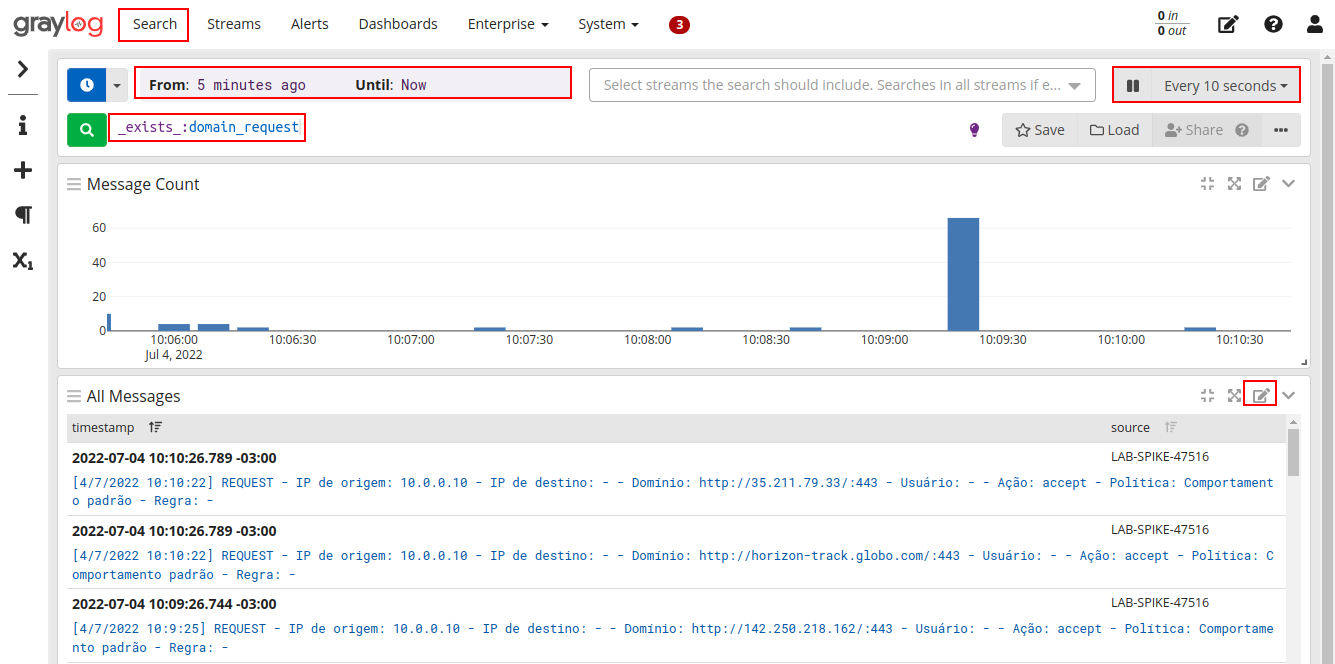
Capturando o domínio a partir da extração, com isso será possível posteriormente criar dashboards presonalizadas:
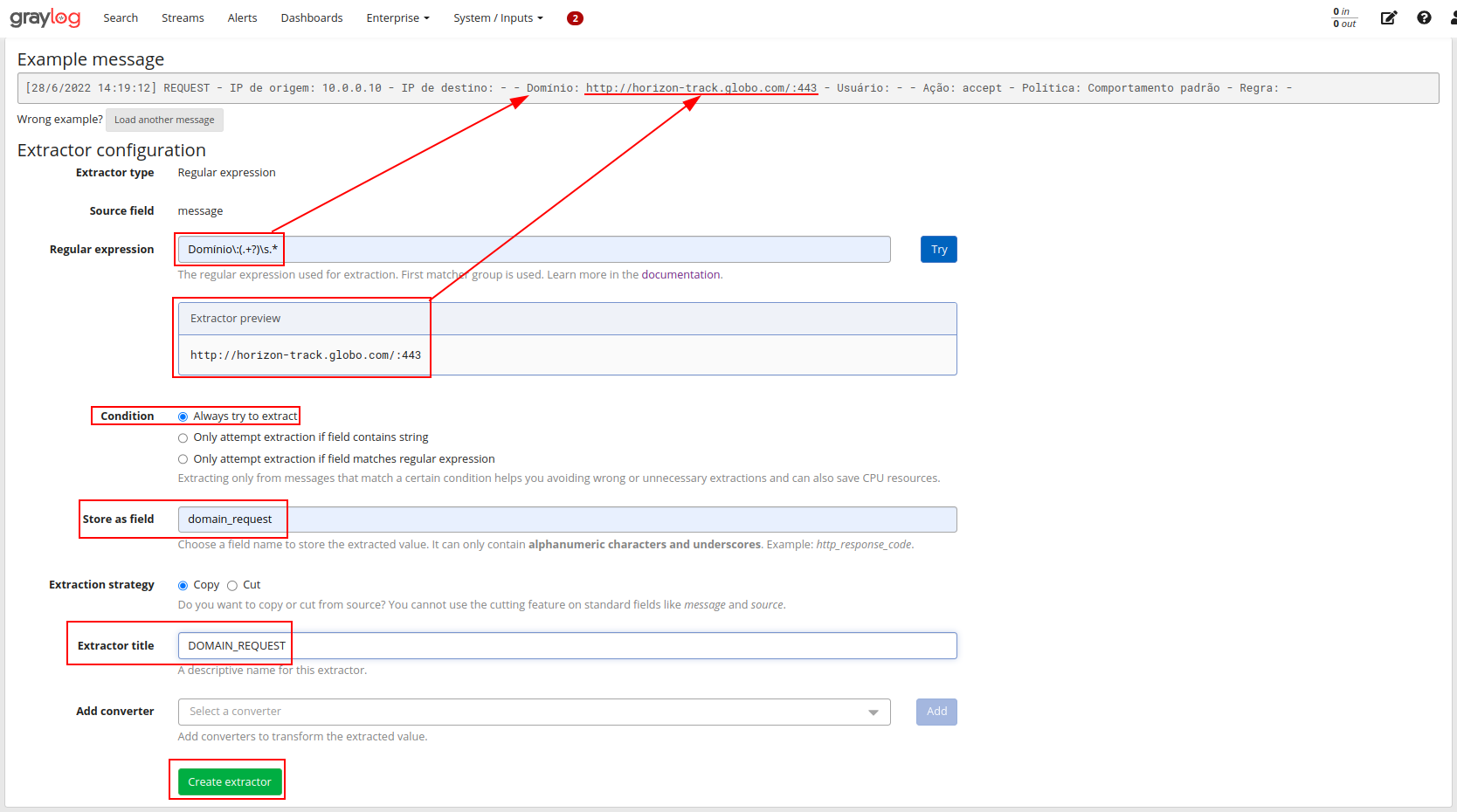
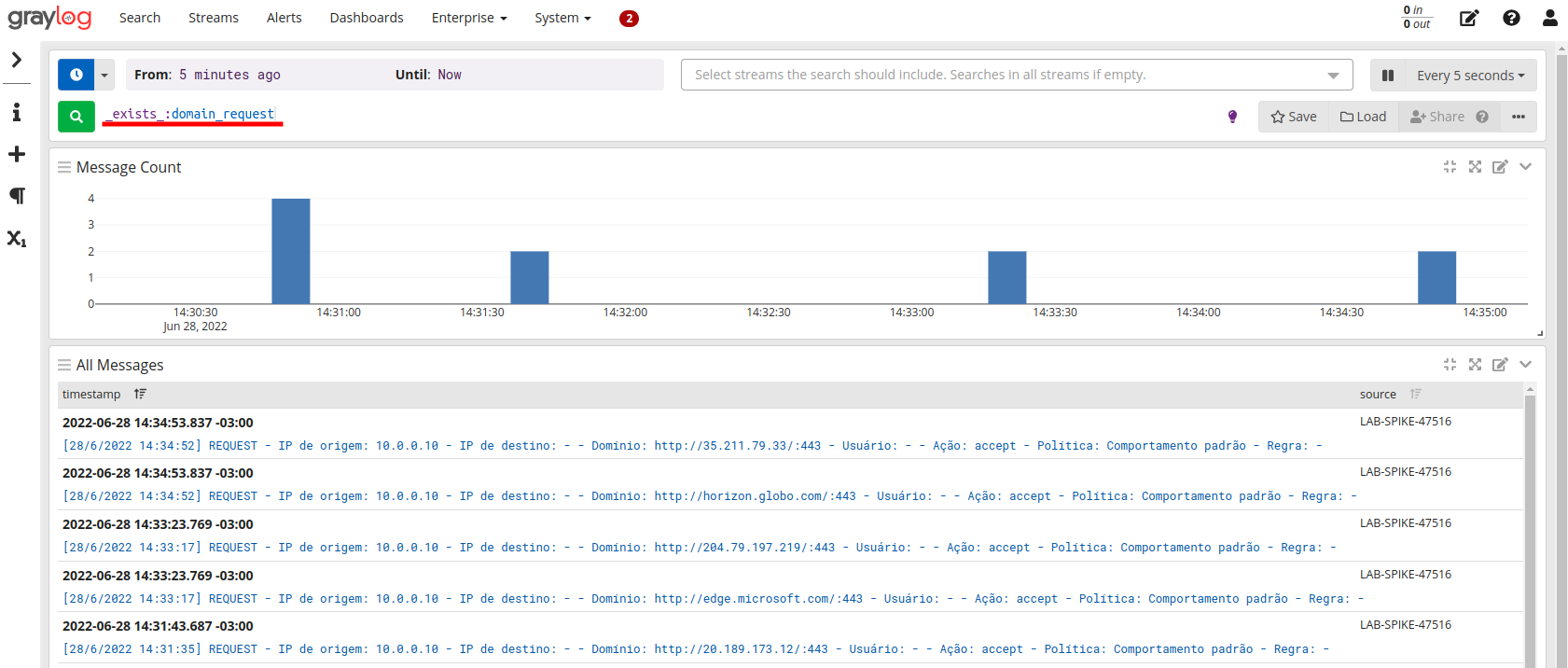
Validando os logs que contenham um domínio conforme nosso extrator:
Criando dashboard simples
Com as configurações de inputs e extratores finalizadas, agora podemos criar nossos dashboards, criando filtros personalizados para exibir as informações necessárias.
Caminho: Interface web -> Dashboards -> Create New Dashboard
Iniciando a criação de uma dashboard:
Para exemplificar o uso de filtros no Dashboard, iremos criar um novo extrator para identificar a ação da política e iremos exibir a contagem de ações accept e ações deny.

Definindo um novo filtro com o extrator que acabamos de criar e editando a exbibição dos dados para um formato mais “amigável”:
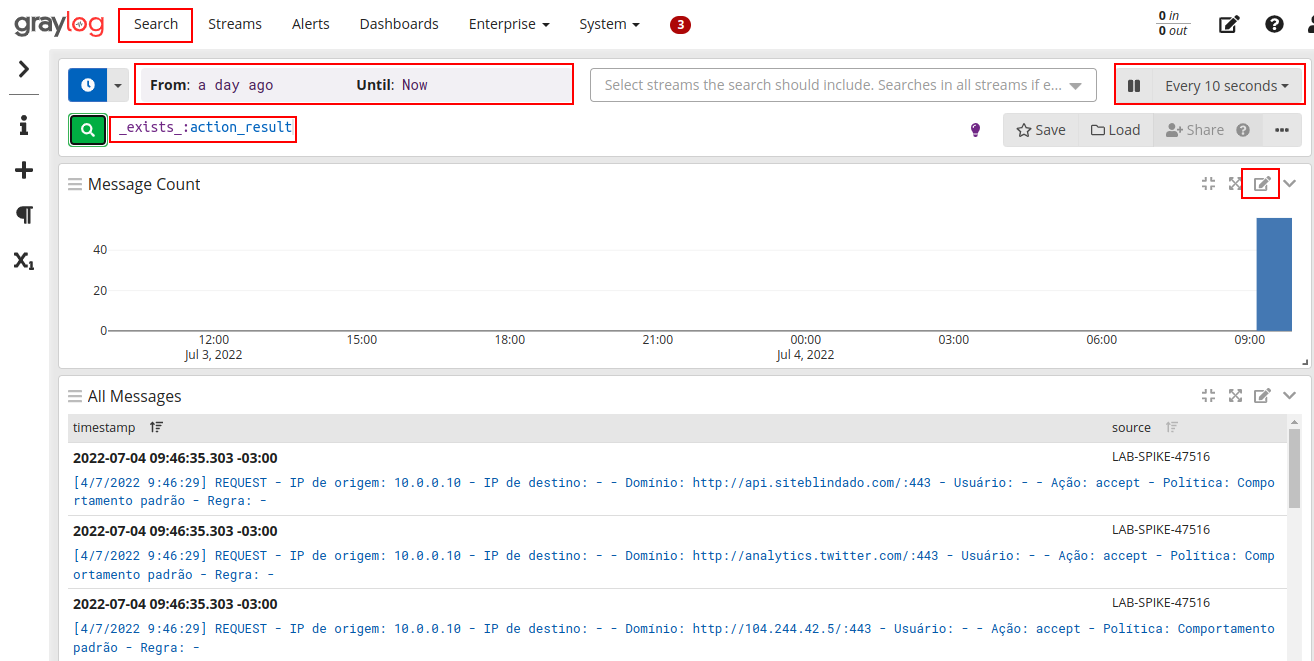
Criando um novo formato de visualização no formato pizza, onde iremos mostrar os dados referente a ação tomada pelo Webfilter (accept ou deny):
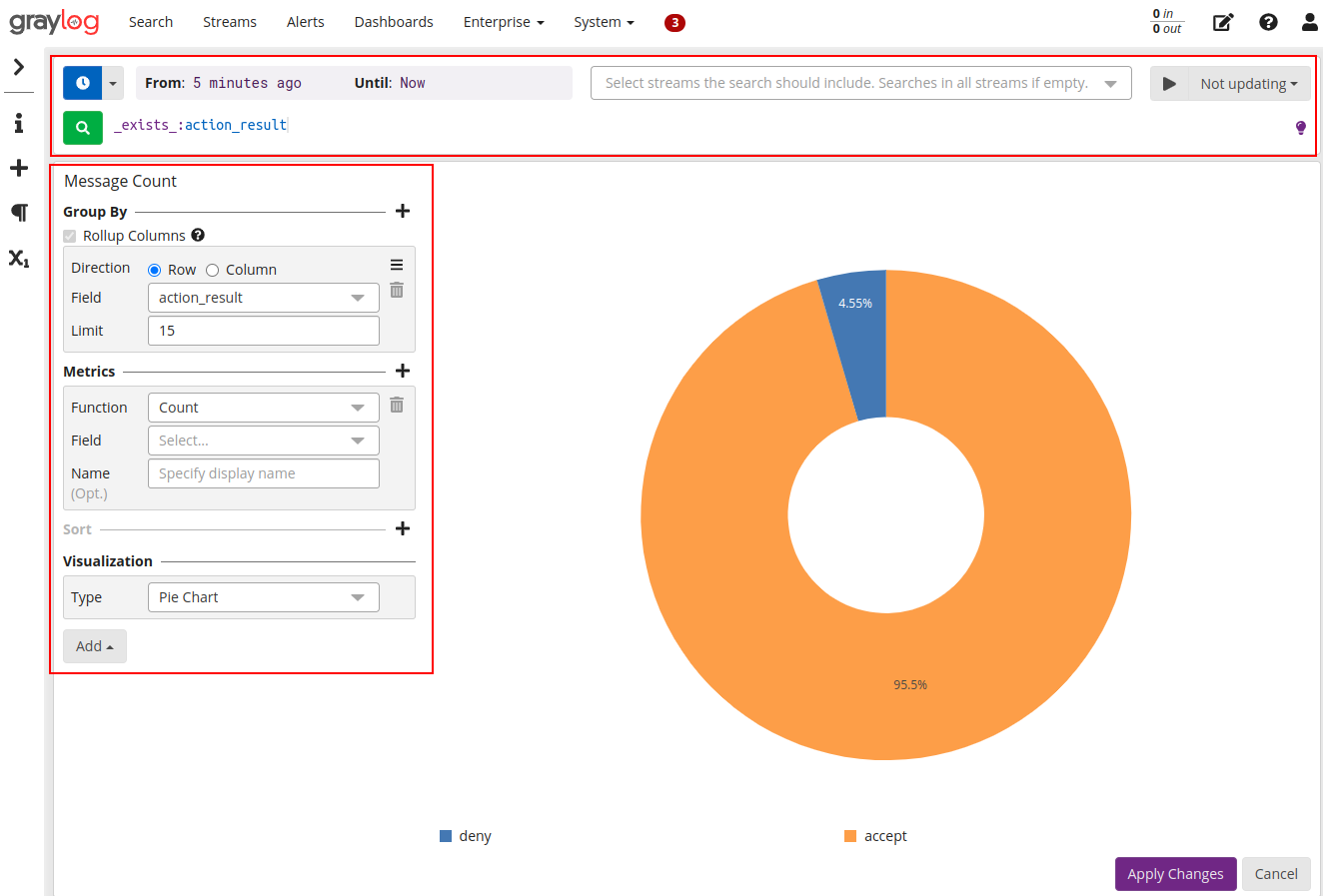
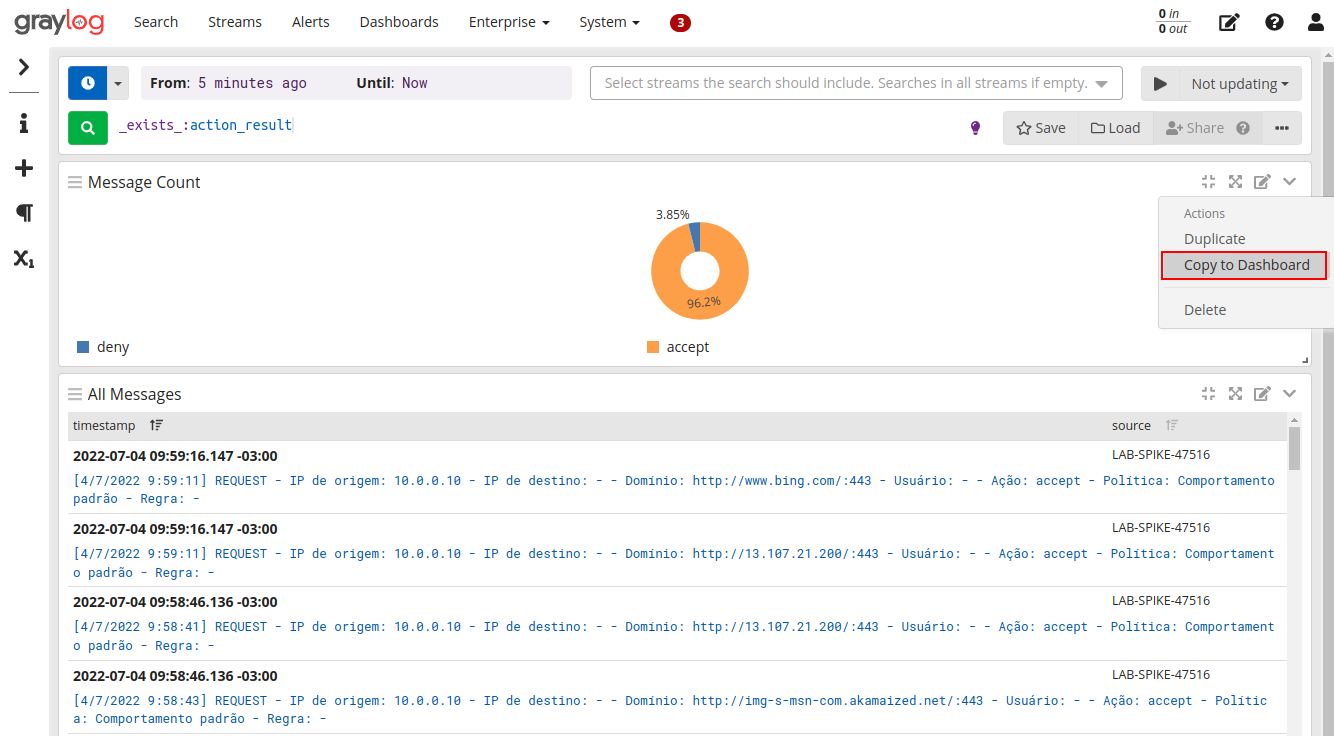
Aplicando o novo gráfico a dashboard que criamos anteriormente:
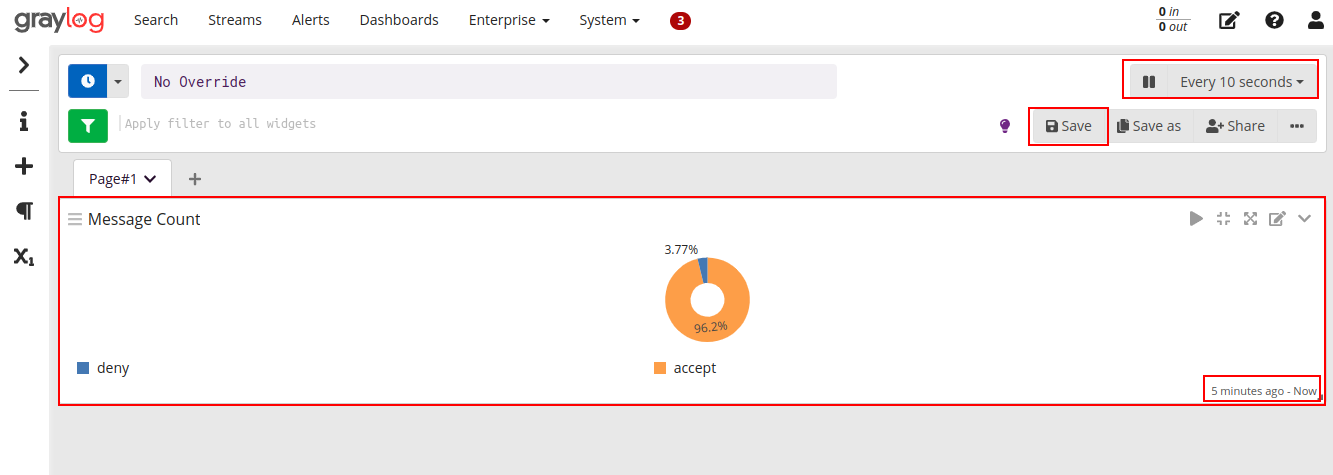
Outro exemplo interessante é exibir o top values, por exemplo uma lista de site de domínios mais acessados.
Criando um novo formato para mostrar os dados, adicionando uma nova coluna a saída de mensagens:
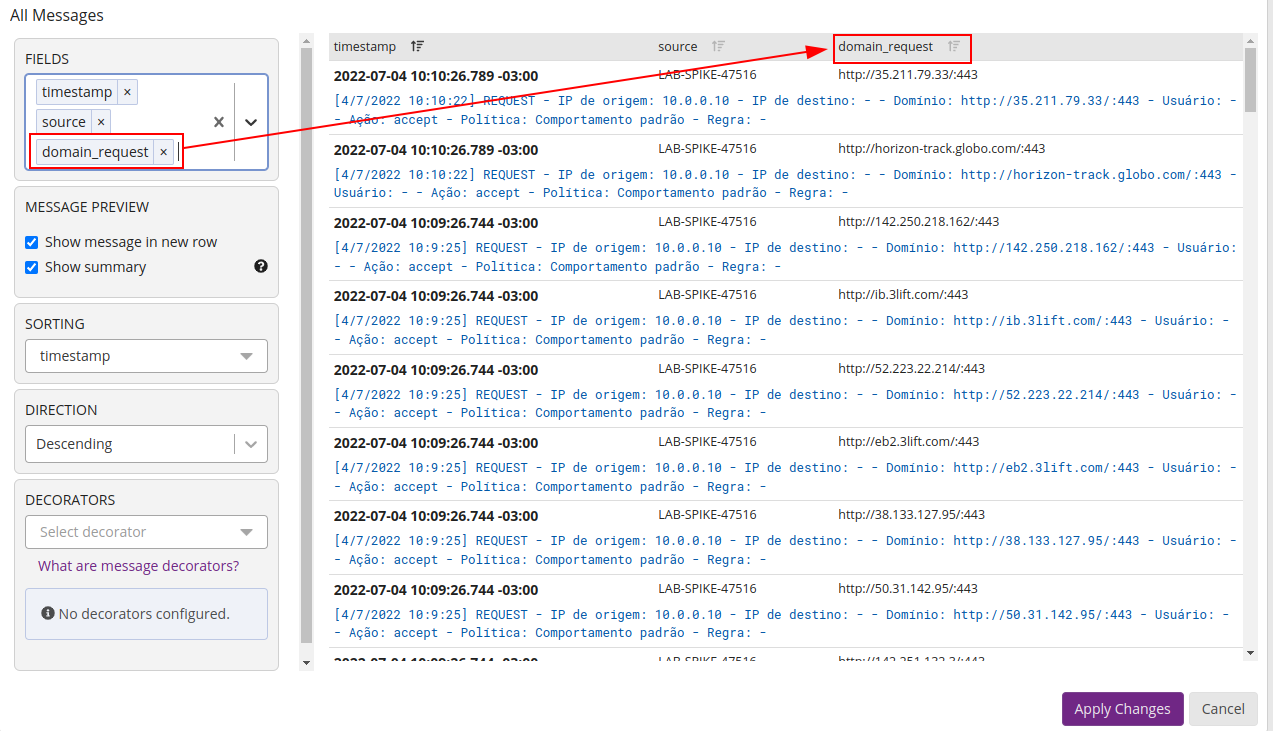
Definindo o filtro para exibir o top values:
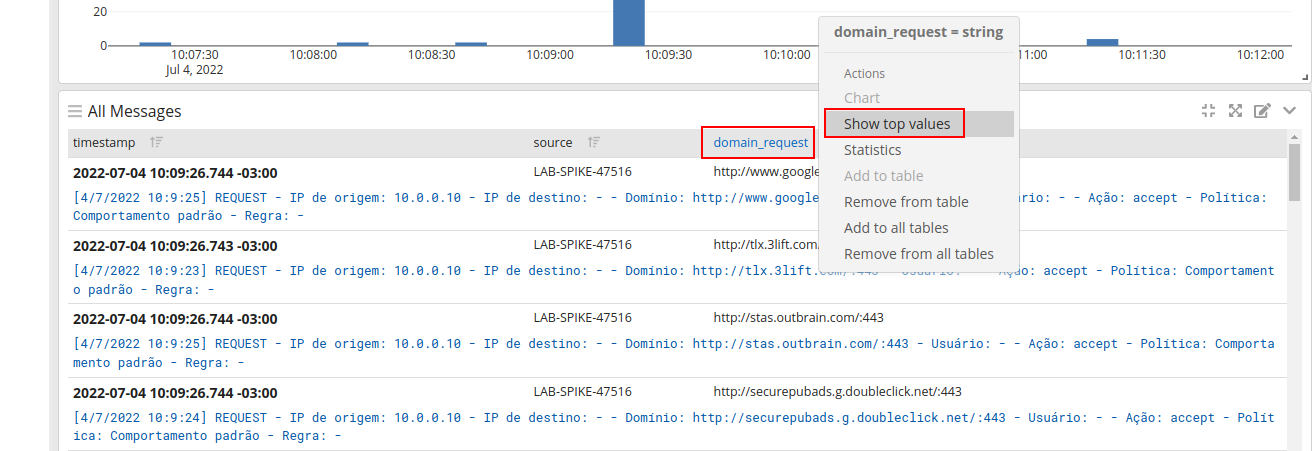
Seguindo o mesmo procedimento para adicionar o gráfico ao dashboard:
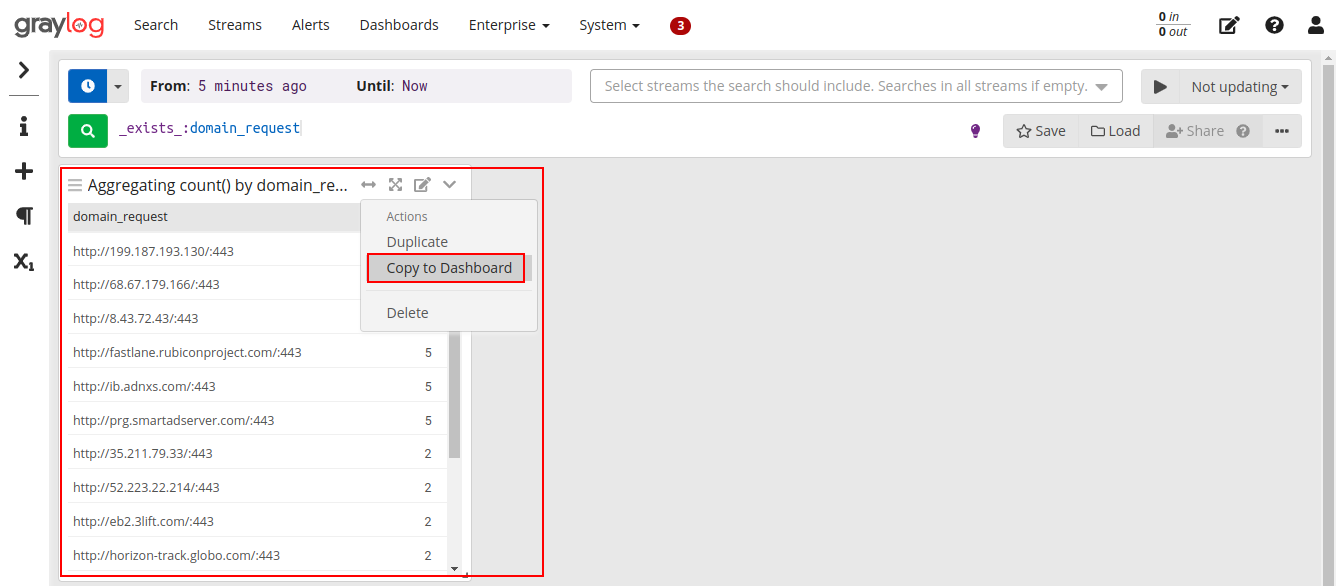
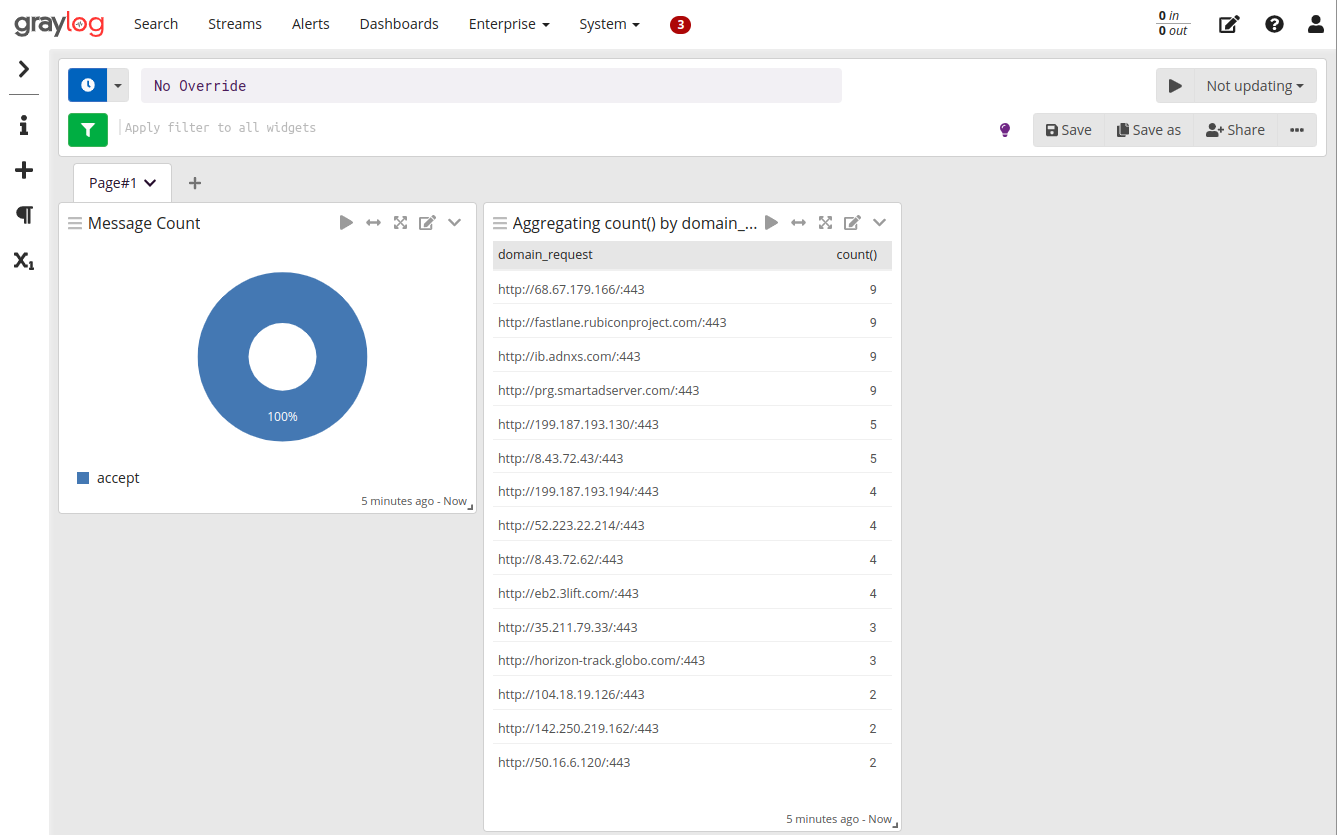
Pronto! Finalizamos nosso simples dashboard, lembrando que é possível efetuar o garimpo mais detalhado de dados, de acordo com a necessidade.
Método para implantação automatizada
Utilizando recurso de backup do MongoDB
Após efetuar a configuração efetuar um DUMP do banco de dados MongoDB, onde estão as configurações efetuadas no Graylog, execute o comando:
mongodump
ls dump/
admin graylog
Parar os serviços do Graylog e ElasticSearch para restaurar o backup do MongoDB:
systemctl stop graylog-server.service
systemctl stop elasticsearch.service
Vamos efetuar o drop do banco graylog existente, para que não ocorram erros no restore:
mongo
> show dbs
admin 0.000GB
config 0.000GB
graylog 0.003GB
local 0.000GB
> use graylog
switched to db graylog
> db.dropDatabase()
{ "dropped" : "graylog", "ok" : 1 }
> exit
bye
Com os serviços do ElasticSearche e Graylogs parados, efetuar o restore (aponte a pasta gerada anteriormente):
mongorestore dump/
2022-07-04T18:13:44.493-0300 preparing collections to restore from
[...]
2022-07-04T18:14:41.467-0300 296 document(s) restored successfully. 0 document(s) failed to restore.
Iniciar os serviços novamente:
systemctl restart mongod.service
systemctl restart elasticsearch.service
systemctl restart graylog-server.service
Agora acesse a interface e valide o backup.
Utilizando recursos de Content Packs
Content Packs é um recurso do Graylog que permite criar um pacote de backup para que possamos exportar e importar em outro Graylog.
Caminho: Interface web -> System -> Content Packs
Vamos criar um novo Content Pack:
Podemos definir o que queremos inserir em nosso pack:
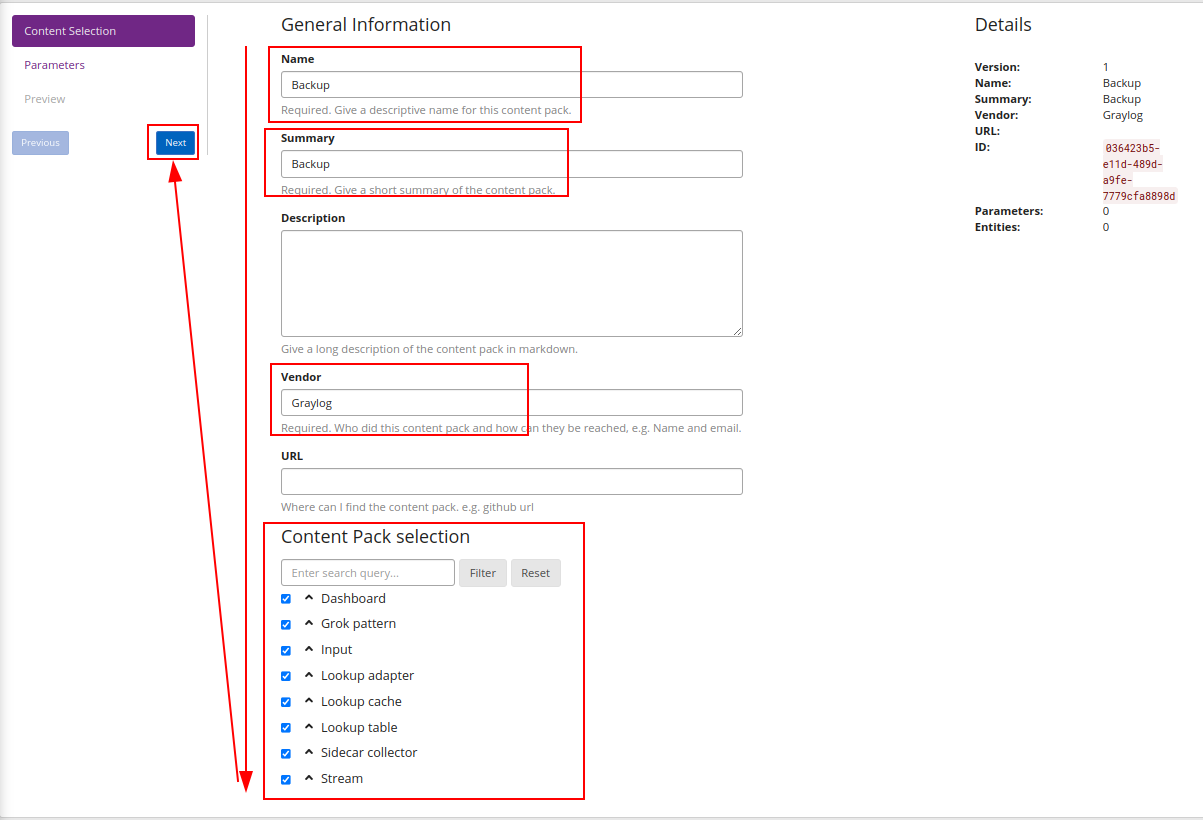
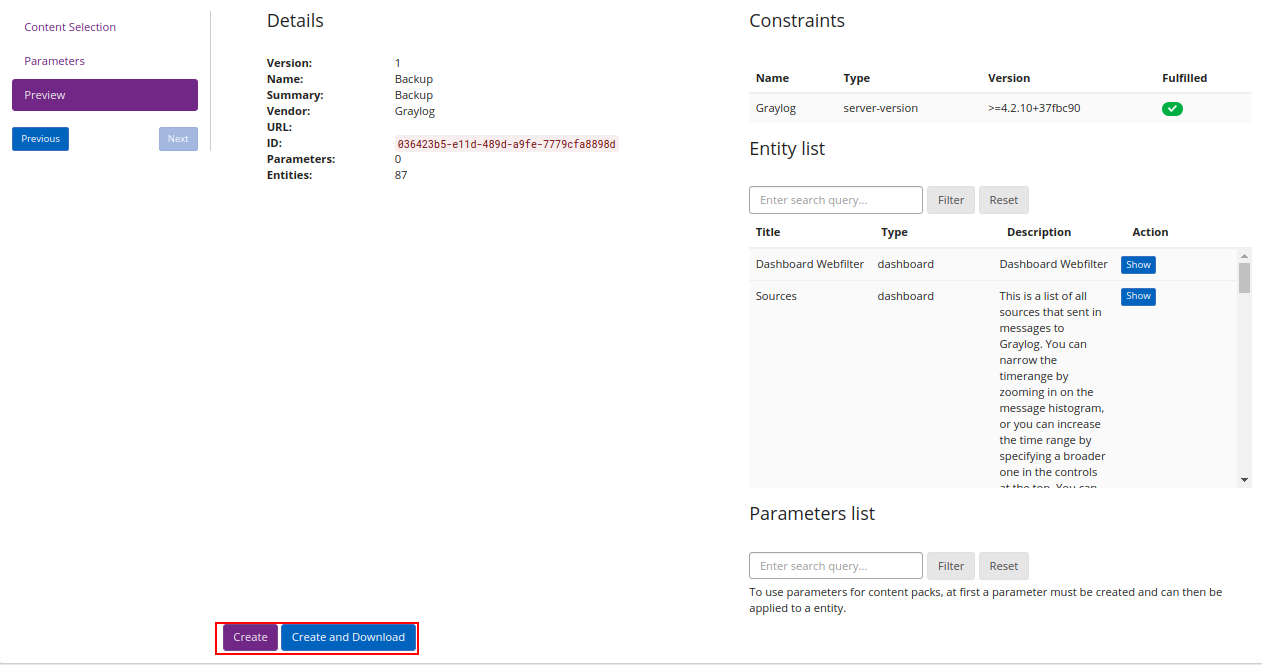
Após finalizar a criação do pacote, teremos ele listado, podemos assim fazer o download do mesmo, um arquivo será baixado e posteriormente usado para importar o conteúdo em outro Graylog.
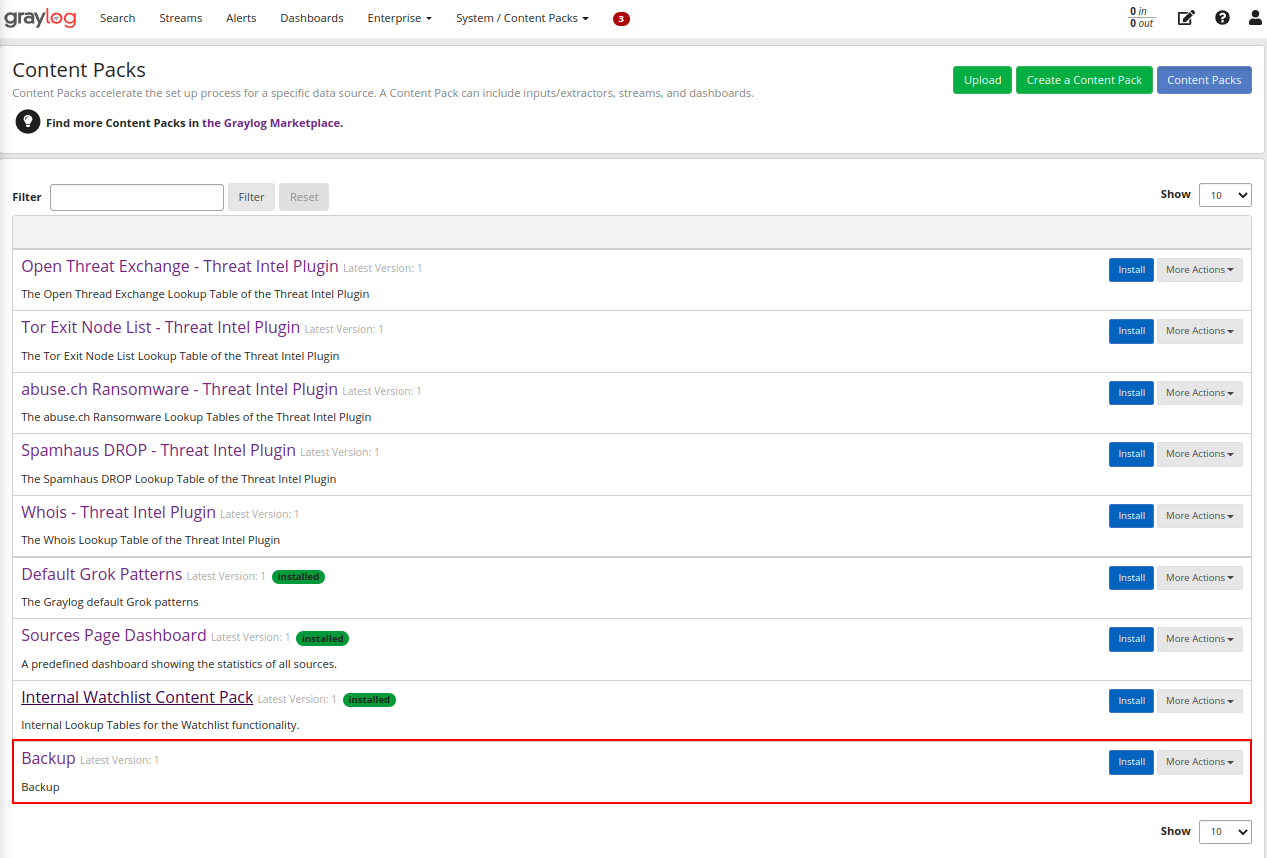
Para importar, vamos até o mesmo caminho e selecionar a opção Upload:
Agora com o pacote importado, podemos instalar ele ao Graylog, ou seja, efetuar o restore:
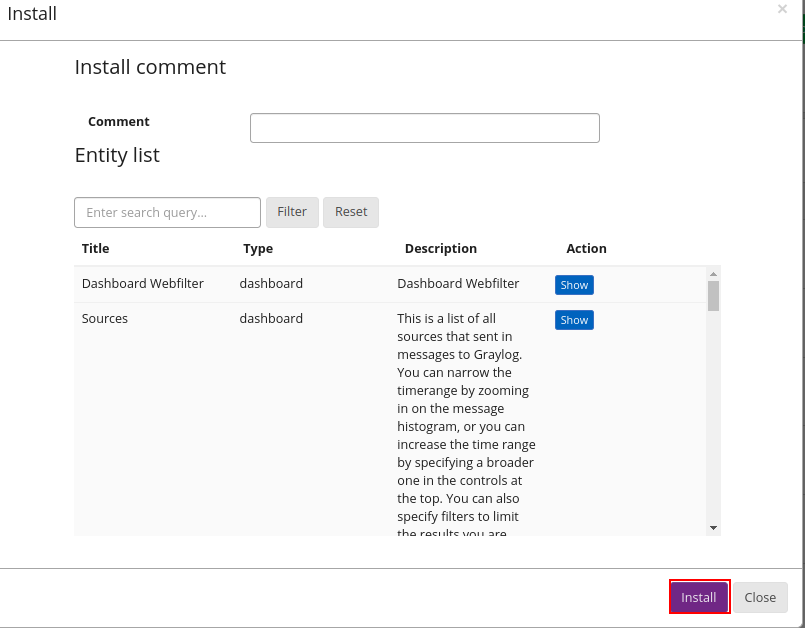

Aqui vale um ponto de atenção, caso já tenhamos dados em nosso Graylog, iguais ao que estão no pacote, os mesmo serão DUPLICADOS, ou seja, crie um pacote apenas do que realmente é necessário e que não contenha em novas implantações do Graylog, para que nenhum dado seja duplicado, como o exemplo abaixo:
Links úteis
- https://www.graylog.org/products/open-source
- https://docs.graylog.org/docs/centos
- https://docs.graylog.org/docs/docker
- https://www.rsyslog.com/doc/v8-stable/configuration/modules/imfile.html
- https://linuxconfig.org/install-docker-on-almalinux
Análise geral
De modo geral, a ferramenta apresenta boa didática e cumpre o que promete. A instalação e configuração básica é simples, porém quando tratamos dos extratores, filtros e dashboards, o funcionamento fica mais complexo. Por usar Java em seu código, utiliza-se um nível alto de consumo de recursos. Além do Graylog, é necessário utilizar outros dois pacotes adicionais, MongoDB para armazenamento das configurações do Graylog e ElasticSearch para o motor de indexação dos logs. A implantação desta funcionalidade ao produto hoje, se torna inviável em ambientes pequenos, visto que o consumo de memória RAM e CPU acabam somando quase 1,5 GB e constante 5% de CPU, pensando em ambientes pequenos com pacotes básicos ativos, teremos firewall, VPN, Webfilter habilitados, causando um throughput considerado, logo a utilização de consumo de logs poderá causar uma latência em I/O, fazendo com que funções básicas do FWFLEX sejam impactadas. A utilização dessa ferramenta faz mais sentido em ambientes maiores, com maior capacidade de processamento, ou até mesmo em uma estrutura externa ao FWFLEX (VM ou servidor bare-metal).
Critérios levados em consideração:
-
Licenciamento: Graylog é uma empresa especializada em tratamento de logs, possuí algumas ferramentas pagas, mas também possuí a versão OpenSource que é a que vamos utilizar.
-
Suporte: Como vimos, existe uma empresa que está mantém o Graylog OpenSource, logo atualizações e patch de correções são lançados constantemente.
-
Instalação: A instalação da ferramenta é simples, assim como a personalização de parâmetros, porém algumas dependências preocupam, além do pacote principal Graylog, é necessário instalar o ElasticSearch (motor de busca do Graylog) que também necessita do Java OpenJDK para execução. No tutorial acima já demonstramos como limitar uso de memória RAM pelo Java. Outra dependência é o MongoDB, hoje não utilizamos no produto, então não gera conflito com as demais funções.
-
Configuração: A configuração é simples na tangente do serviço, a configuração de
inputs,extratoresedashboardsrequerem um nível de conhecimento maior, pois está relacionado com criação de regex e outros parâmetros. -
Integração com o produto: Inserir esta funcionalidade ao produto irá implicar em aumento de consumo de recursos a curto prazo e poderá impactar nos serviços básicos do FWFLEX.
-
Performance: Quando instalado em máquina
bare-metalfica um pouco mais abstrato validar o consumo de recursos, em Docker fica um pouco mais claro, conforme print abaixo:
-
Limitações/impedimentos/riscos: O uso em laboratório a ferramenta se comporta de modo geral bem e entrega o que promete. Instalado em máquina ou executando através de container, o funcionamento aparente ser o mesmo, recebendo e tratando os logs do Webfilter via Syslog/UDP. O maior risco é a performance, como vimos no passo anterior, devido ao número de serviços (Graylog, MongoDB e ElasticSearch) o uso acaba sendo um pouco alto, em servidores com menor poder de processamento, pode acabar impactando na performance do mesmo, tendo isso em vista, um possível futuro problema é o I/O de disco.
-
Referência de soluções alternativas: Pensamos em utilizar algum outro tipo de serviço, como NTOP, SquidAnalizer, etc.