Por: @eduardoh Publicado em: 2022-07-29
Prometheus exportando métricas do hardware do servidor
Objetivo
Validar o funcionamento do Prometheus exportando métricas do hardware do servidor para que seja possível consolidar essas métricas na interface do FWFLEX exibindo um histórico de consumo dos recursos, como CPU, memória, disco, etc.
Instalação
O Prometheus já vem instalado no FWFLEXv3, então essa etapa não é necessária para aplicação no produto.
Para o laboratório, utilizamos uma imagem limpa do AlmaLinux.
Como não vamos utilizar o produto ainda, vamos executar o Prometheus via Docker, para facilitar a configuração do ambiente, etc.
Preparando o ambiente
Como trata-se de uma instalação limpa do AlmaLinux, lembre-se de desativar o SELinux e também o FirewallD:
setenforce 0
sed -i 's|SELINUX=enforcing|SELINUX=disabled|g' /etc/selinux/config
systemctl stop firewalld
systemctl disable firewalld
Instalando o Docker no AlmaLinux
Para executar o Prometheus, será necessário instalarmos o Docker no AlmaLinux:
dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
dnf install docker-ce docker-ce-cli containerd.io
Garantindo que o serviço será inicializado com o sistema:
systemctl start docker
systemctl enable docker
Executando container do Prometheus
Para o laboratório, iremos executar o Prometheus do formato mais simples possível, sem utilizar volume externo, segmentação de rede ou qualquer configuração avançada, para isso, execute o container do Prometheus.
Antes vamos preparar um arquivo de configuração do Prometheus, seguindo o padrão que utilizamos no produto (lembrando de alterar os targets conforme necessário):
vim /root/prometheus.yml
global:
scrape_interval: 5s
scrape_configs:
- job_name: "collectd"
static_configs:
- targets: ["localhost:9103"]
Agora vamos de fato criar nosso container utilizando nosso arquivo como padrão:
docker run --name prometheus --rm -d -p 9090:9090 -v /<diretório>/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus
docker run: Indica que iremos executar um container simples--name prometheus: Indica o nome do container--rm: Quando parado o container, ele irá se excluir automaticamente-d: Define o container para ser executado em background-p 9090:9090: Está mapeando a porta do serviço Prometheus do container para a porta no host, ambas na porta 9090-v /<diretório>/prometheus.yml:/etc/prometheus/prometheus.yml: Significa que estamos mapeando uma arquivo local para dentro do containerprom/prometheus: Indica qual imagem iremos utilizar para executar nosso container
Após executar, já podemos ir no navegador e validar se a interface do Prometheus está em execução:
Podemos validar também se as métricas estão sendo expostas corretamente, basta acrescentar /metrics a URL:
Instalando collectd para extração de métricas do host
Hoje já utilizamos o collectd no produto para exposição e extração dos logs, então no nosso laboratório vamos precisar instalar o mesmo pacote.
No produto temos os seguintes pacotes marcados como spec:
Requires: collectd >= 5.9
Requires: collectd-write_prometheus >= 5.9
Requires: collectd-netlink >= 5.9
Este pacote faz parte do repositório epel, então como é uma instalação limpa do AlmaLinux, devemos instalar também:
yum install epel-release
yum update
Instalando os pacotes do collectd:
yum install collectd collectd-write_prometheus collectd-netlink
Para dar sequência no cenário, vamos copiar um exemplo do arquivo /etc/collectd.conf que temos no produto, para sermos fieis ao ambiente de produção do FWFLEX:
#Hostname "localhost"
#FQDNLookup true
#BaseDir "/var/lib/collectd"
#PIDFile "/var/run/collectd.pid"
#PluginDir "/usr/lib64/collectd"
#TypesDB "/usr/share/collectd/types.db"
Interval 5
#MaxReadInterval 86400
#Timeout 2
#ReadThreads 5
#WriteThreads 5
# Logging #
#----------------------------------------------------------------------------#
LoadPlugin logfile
<Plugin logfile>
LogLevel info
File STDOUT
Timestamp true
PrintSeverity false
</Plugin>
# LoadPlugin section #
#----------------------------------------------------------------------------#
LoadPlugin netlink
LoadPlugin write_prometheus
# Plugin configuration #
#----------------------------------------------------------------------------#
<Plugin netlink>
Interface "All"
QDisc "All"
Class "All"
Filter "All"
</Plugin>
<Plugin write_prometheus>
Port "9103"
</Plugin>
Include "/etc/collectd.d"
Lembre-se de reiniciar e habilitar a inicialização do serviço:
systemctl enable collectd
systemctl restart collectd
Com essas configurações, teremos um padrão de envio de métricas de do plugin netlink que captura informações de rede.
Nosso objetivo é tratar informações do hardware, então vamos ativar alguns outros plugins para termos essa extração personalizada.
No mesmo arquivo /etc/collectd.conf, adicione o seguinte (seguindo a ordem dentro do arquivo de configuração):
[...]
# LoadPlugin section #
#----------------------------------------------------------------------------#
LoadPlugin load
LoadPlugin memory
LoadPlugin disk
[...]
# Plugin configuration #
#----------------------------------------------------------------------------#
[...]
<Plugin disk>
Disk "/^[hs]d[a-f][0-9]?$/"
IgnoreSelected false
</Plugin>
[...]
Antes de reiniciarmos o serviço, precisamos instalar um plugin adicional que não utilizamos no produto, trata-se do plugin de disco, para isso, execute o seguinte:
yum install collectd-disk -y
Agora podemos reiniciar o collectd.
Certifique-se que o serviço está no ar. Acompanhe os logs, deverá aparecer algo assim:
ago 01 08:43:16 LAB-SPIKE-47630 collectd[4537]: [2022-08-01 08:43:17] plugin_load: plugin "logfile" successfully loaded.
ago 01 08:43:16 LAB-SPIKE-47630 collectd[4537]: [2022-08-01 08:43:17] plugin_load: plugin "load" successfully loaded.
ago 01 08:43:16 LAB-SPIKE-47630 collectd[4537]: [2022-08-01 08:43:17] plugin_load: plugin "memory" successfully loaded.
ago 01 08:43:16 LAB-SPIKE-47630 collectd[4537]: [2022-08-01 08:43:17] plugin_load: plugin "disk" successfully loaded.
ago 01 08:43:16 LAB-SPIKE-47630 collectd[4537]: [2022-08-01 08:43:17] plugin_load: plugin "netlink" successfully loaded.
ago 01 08:43:16 LAB-SPIKE-47630 collectd[4537]: [2022-08-01 08:43:17] plugin_load: plugin "write_prometheus" successfully loaded.
ago 01 08:43:16 LAB-SPIKE-47630 collectd[4537]: [2022-08-01 08:43:17] Systemd detected, trying to signal readiness.
ago 01 08:43:16 LAB-SPIKE-47630 collectd[4537]: [2022-08-01 08:43:17] write_prometheus plugin: Listening on [::]:9103.
ago 01 08:43:16 LAB-SPIKE-47630 collectd[4537]: [2022-08-01 08:43:17] Initialization complete, entering read-loop.
A partir de agora já temos métricas exportadas relacionadas load, memory e disk. Podemos verificar se as métricas estão sendo importadas, acessando pelo navegador a URL http://<IP>:9103/metrics
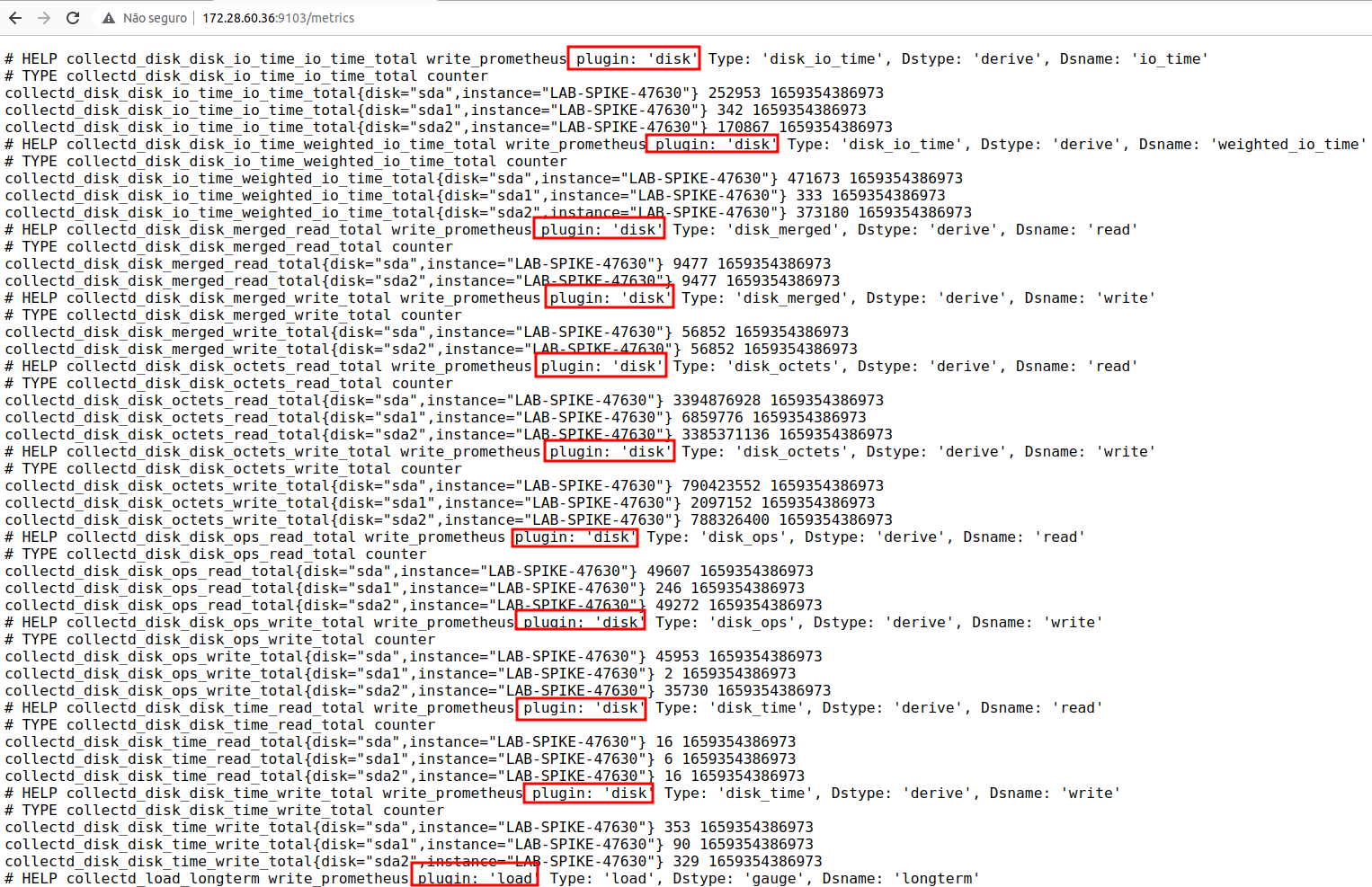
O produto FWFLEX precisa as métricas expostas dessa maneira, agora ele já consegue interagir extraindo e montando dashboards (como já acontece nas métricas de interfaces de rede).
Exportando métricas da nossa aplicação
Visando o futuro do produto, decidimos inserir na documentação um exemplo de integração de instrumentação de aplicação utilizando bibliotecas nativas do Prometheus.
Com elas é possível exportarmos métricas da nossa aplicação core, para isso deixo aqui uma documentação de exportação de métricas utilizando a lib do Python, mas existem para várias outras linguagens.
Para o nosso exemplo, vamos utilizar uma imagem de Docker do NodeJS, com um código simples, apenas para mostrar os acessos HTTP que tivemos a nossa aplicação.
Vamos criar nosso diretório onde terão os arquivos da nossa aplicação:
mkdir /root/myapp
Agora vamos criar três arquivos dentro dessa pasta:
Dockerfile
FROM node:12-alpine
RUN mkdir -p /home/node/app/node_modules && chown -R node:node /home/node/app
WORKDIR /home/node/app
COPY package*.json ./
USER node
RUN npm install
COPY --chown=node:node . .
EXPOSE 3000
CMD [ "node", "app.js" ]
app.js
var express = require('express');
var promClient = require('prom-client');
const register = promClient.register;
var app = express();
const counter = new promClient.Counter({
name: 'myapp_request_total',
help: 'Contador de requests',
labelNames: ['statusCode']
});
const gauge = new promClient.Gauge({
name: 'myapp_free_bytes',
help: 'Exemplo de gauge'
});
const histogram = new promClient.Histogram({
name: 'myapp_request_time_seconds',
help: 'Tempo de resposta da API',
buckets: [0.1, 0.2, 0.3, 0.4, 0.5]
});
const summary = new promClient.Summary({
name: 'myapp_summary_request_time_seconds',
help: 'Tempo de resposta da API',
percentiles: [0.5, 0.9, 0.99]
});
app.get('/', function (req, res) {
counter.labels('200').inc();
counter.labels('300').inc();
gauge.set(100 * Math.random());
const tempo = Math.random();
histogram.observe(tempo);
summary.observe(tempo);
res.send('Hello World!');
});
app.get('/metrics', async function (req, res) {
res.set('Content-Type', register.contentType);
res.end(await register.metrics());
})
app.listen(3000);
package.json
{
"name": "app",
"version": "1.0.0",
"description": "",
"main": "app.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "",
"license": "ISC",
"dependencies": {
"express": "^4.16.4",
"prom-client": "^13.0.0"
}
}
Próximo passo será gerar uma imagem Docker que contenha nossa aplicação de exemplo:
cd /root/myapp/
docker build -t myapp:latest .
Agora podemos executar nossa imagem e ver o resultado pelo navegador:
docker run --name myapp -p 3000:3000 -d --rm myapp:latest
No navegador, basta colocar o IP do servidor seguido da porta 3000, e para acessar as métricas exportadas pela lib do Prometheus, basta indicar a URI /metrics:
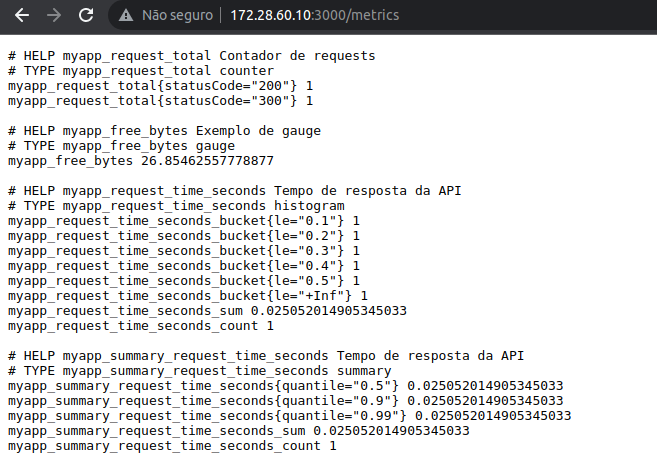
Lembrando, que isso é um exemplo de como extrair métricas de uma aplicação. Sugestão seria avaliar se teríamos dados necessários e interessantes para exportar num futuro.
A última etapa é adicionar um novo target ao Prometheus, apontando nossa aplicação NodeJS. Para isso, no arquivo prometheus.yml criado lá no início do tutorial para rodar nosso Prometheus, iremos adicionar ao final dele as seguintes linhas:
- job_name: "myapp"
static_configs:
- targets: ["172.28.60.10:3000"]
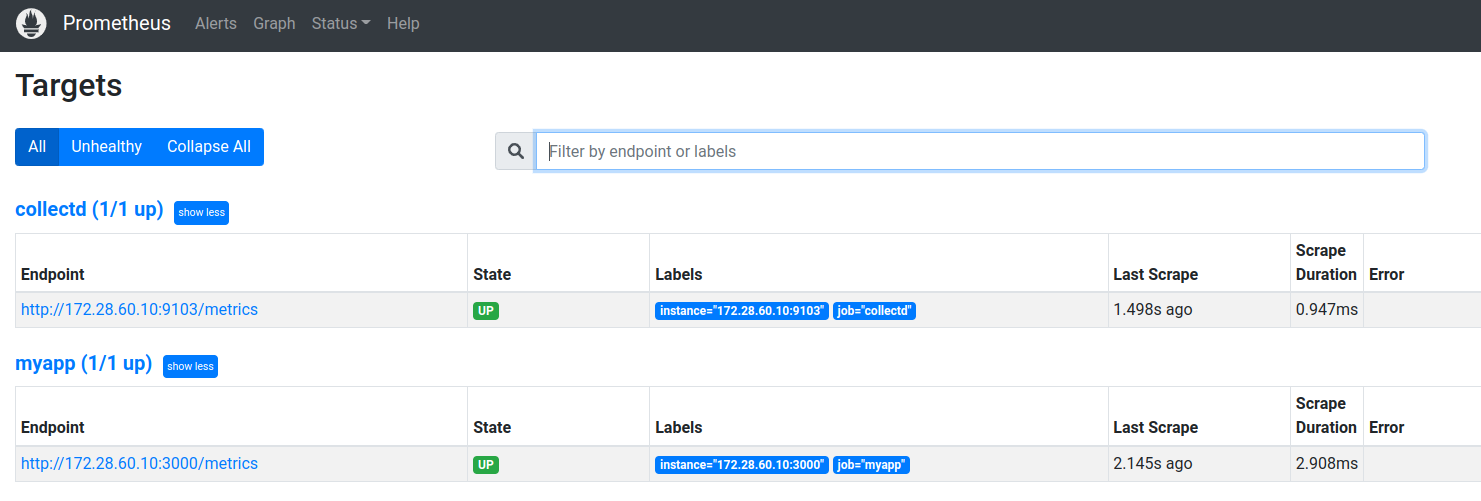
Agora teremos mais um target disponível em nosso Prometheus e novas métricas sendo coletadas:
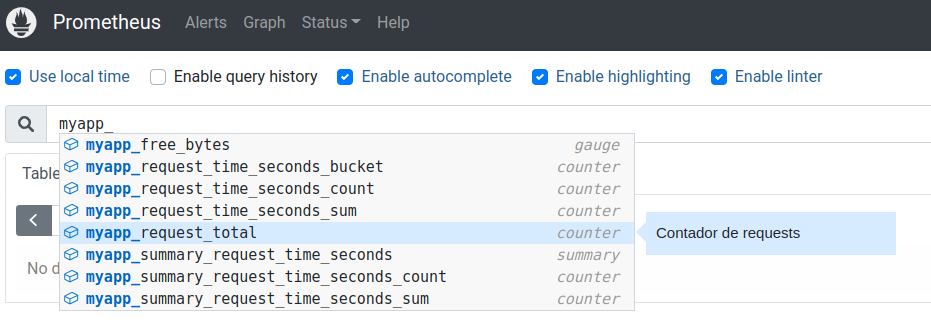
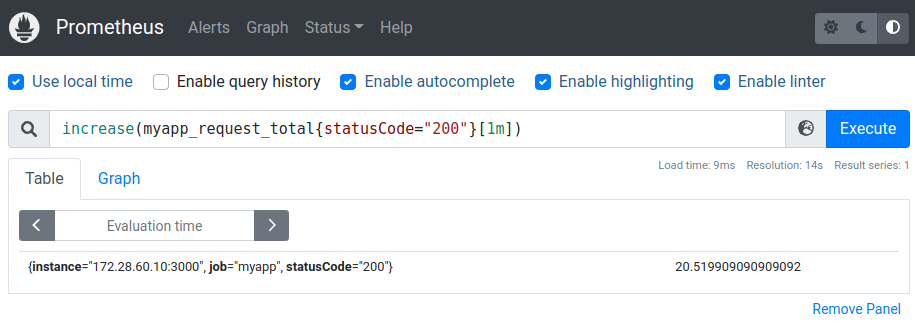
Já podemos inclusive utilizar nossas métricas nos filtros do Prometheus (veremos detalhes de filtros no próximo tópico):
Estruturando uma Query em PromQL
PromQL é a linguagem que o Prometheus utiliza para executar suas queries no TSDB. Um ponto importante de salientar é que o Prometheus exibe suas métricas em UTC, então para exibição dos dados coletados devemos considerar esse aspecto. Caso necessário, no laboratório, utilize uma calculadora de timestamp online aqui!
Assim que compreendemos o que é o Prometheus e como aplicar no formato mais simples possível, conseguimos entender suas partes, e uma das mais importantes é o PromQL. Precisamos documentar alguns conceitos importantes para o entendimento mais aprofundado e como iremos estruturar nossas queries no futuro.
Tipos de dados
O Prometheus classifica alguns tipos de dados coletados e o que eles significam para termos uma maior calibragem no que filtrar, são eles:
Vector: retorna número inteiro.
Exemplo:
-> Chave: http_requests_total
-> Resultado: http_requests_total{method="POST", code "200"}
Instant Vector: retorna valores de uma série temporal num instante de tempo.
Exemplo:
-> Chave: http_requests_total (@31/12/2019 23:58:00)
-> Resultado: http_requests_total{method="POST", code "200"} -> 274 acessos
Range Vector: retorna valores de uma série temporal num range de tempo.
Exemplo:
-> Chave: http_requests_total[1m] (@31/12/2019 23:58:00)
-> Resultado:
23:57:00 -> http_requests_total{method="POST", code "200"} -> 2 acessos
23:57:15 -> http_requests_total{method="POST", code "200"} -> 5 acessos
23:57:30 -> http_requests_total{method="POST", code "200"} -> 7 acessos
23:57:45 -> http_requests_total{method="POST", code "200"} -> 8 acessos
23:58:00 -> http_requests_total{method="POST", code "200"} -> 10 acessos
Filtros
O Prometheus nos permite efetuar uma gama grande de filtros, como vimos no passo anterior, filtramos dados de acesso ao nosso app baseado no código de retorno HTTP 200.
Acesse a documentação oficial para verificar outros exemplos.
Outro filtro bastante comum de ser utilizado, são as labels. O exemplo do código HTTP 200 é um exemplo de filtro por label. Vamos demonstrar agora alguns filtros utilizando o collectd e visualizando dados do nosso hardware.
Uma métrica que vamos utilizar do collectd é o load do servidor. Para isso temos a disposição as seguintes métricas coletadas:
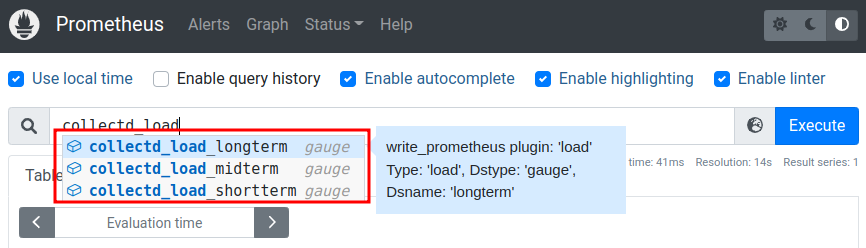
Sendo:
shortterm: Load de 1mmidterm: Load de 5mlongterm: Load de 15m
Filtrando por um deles, podemos notar que é coerente com o atual load do servidor:
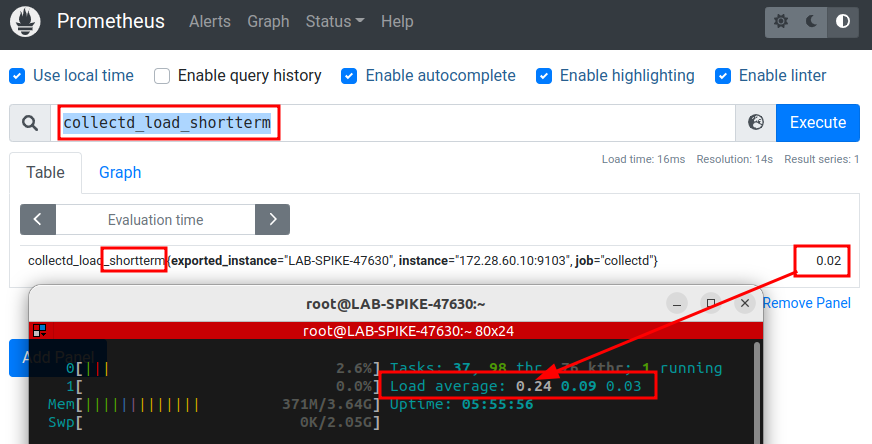
Outro exemplo interessante seria utilizarmos uma concatenação nos filtros, igual demonstrado no exemplo do tópico Tipos de dados.
Vamos coletar agora os dados de memória RAM do servidor, livre ou em uso. Para isso vamos utilizar expressões regulares:

Lembrando que os dados precisam ser calculados para o formado necessário antes de exibir para o usuário.
Links úteis
- https://prometheus.io/
- https://prometheus.io/docs/introduction/overview/
- https://github.com/prometheus/collectd_exporter
- https://github.com/prometheus/node_exporter
- https://collectd.org/
- https://collectd.org/wiki/index.php/Main_Page
- https://prometheus.io/docs/instrumenting/clientlibs/
- https://faun.pub/how-to-build-a-node-js-application-with-docker-f596fbd3a51
Análise geral
nonono
Critérios levados em consideração:
-
Licenciamento: nonono
-
Suporte: nonono
-
Instalação: nonono
-
Configuração: nonono
-
Integração com o produto: nonono
-
Performance: nonono
-
Limitações/impedimentos/riscos: nonono
-
Referência de soluções alternativas: nonono